role & responsibilities
product designer, user researcher
End to end product design (wireframes, high-fidelity mockups, interaction spec), user research facilitation, iteration & integration of user feedback, stakeholder presentation
project duration: 3 months concurrently with 2 other projects
background
The Twitter Knowledge Graph contains all entities contained within and related to Twitter, defined by basic types (e.g. Tweet, Timeline) and composed types created by Twitter users of the Knowledge Graph.
Users of the Knowledge Graph (e.g. Product Managers, Data Analysts, Engineers) need to create composed entities for queries for their own specific projects within Twitter.
problem
The current way to add new entities and fields to the Knowledge Graph is to write schemas in their native JSON format with no real-time validation or guidance, a near-impossible and time consuming task for those unfamiliar with writing schemas. Additionally, certain classes of entities and their fields have specific requirements which require the user to research and cross-reference from disparate and often incomplete documentation.
This process of writing schemas directly results in large amounts of time wasted generating invalid, poorly documented schemas with hard to diagnose syntax and composition errors, or entire teams waiting indefinitely for a schema writing resource to become available.
process
When approaching solving the problems with schema generation described above, I followed my Design Science process which combines Design Thinking with the Scientific Method.
The Twitter Graph team approached me with the current status (a simple schema explorer) and an ask; a schema builder that is accessible to all users, not just those adept at writing schemas in their native JSON format.
lit review & research
As part of my literature review before beginning any ideation work, I met frequently with the Twitter Graph team to understand the current state and expected requirements for the Schema Builder.
I additionally met with current users from each of the personas (Data Engineer, Data Analyst, Product Manager) expected to use Schema Builder to understand their experiences using the current state and identify major areas for improvement.
Another key part of my literature review involved researching existing schema exploration and building tools, IDEs, and drawing on my own experience designing tools that enable non-SMEs to build and use complicated technical artifacts.

Stakeholder pitch sketch
experimental design
Designing an experiment is next in the Design Science process and will enable us to test our design hypothesis. The ask for this project, a schema builder that is accessible to all users, is fairly well defined such that we can pose a simple experiment: any persona can self-create a valid, usable schema within our new framework.
hypothesis / proposed solution
A standard schema builder with embedded, real-time context-aware validation and guidance including a dynamic code / no code experience will provide a fast, easy way for all users of the Twitter Knowledge Graph to generate valid, usable schemas.
requirements
Requirements were defined with the Knowledge Graph API team and synthesis of data from Knowledge Graph user interviews.
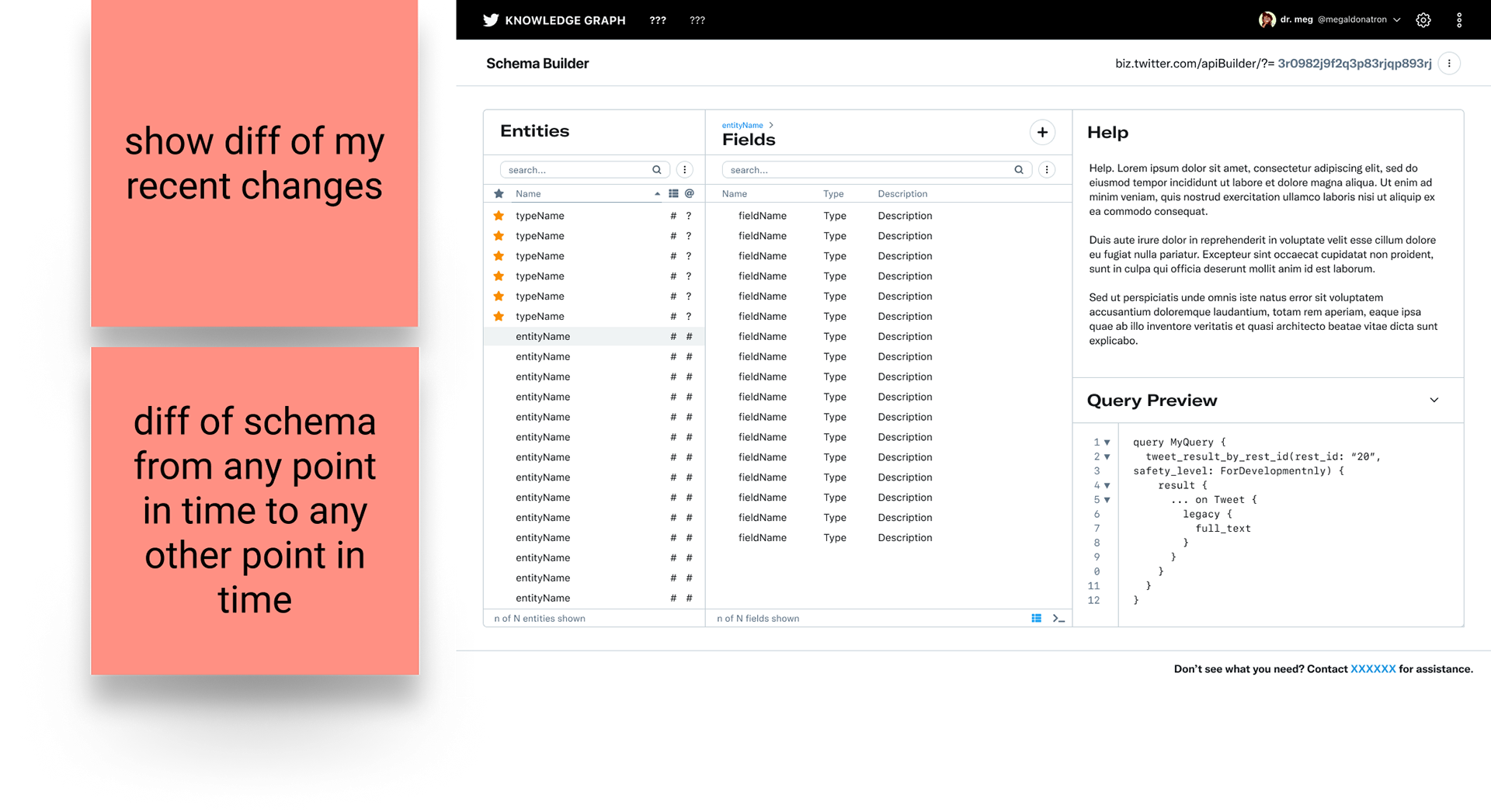
explore flow - load a schema from its unique identifier; explore its entities and their related fields
add new flow - add new entities or fields to a schema with a guided form-based validator experience - or - code editing experience with context-aware code completion and the ability to switch between the two
history flow - audit changelog of schema edits
revert flow - diff & revert to previous version of schema
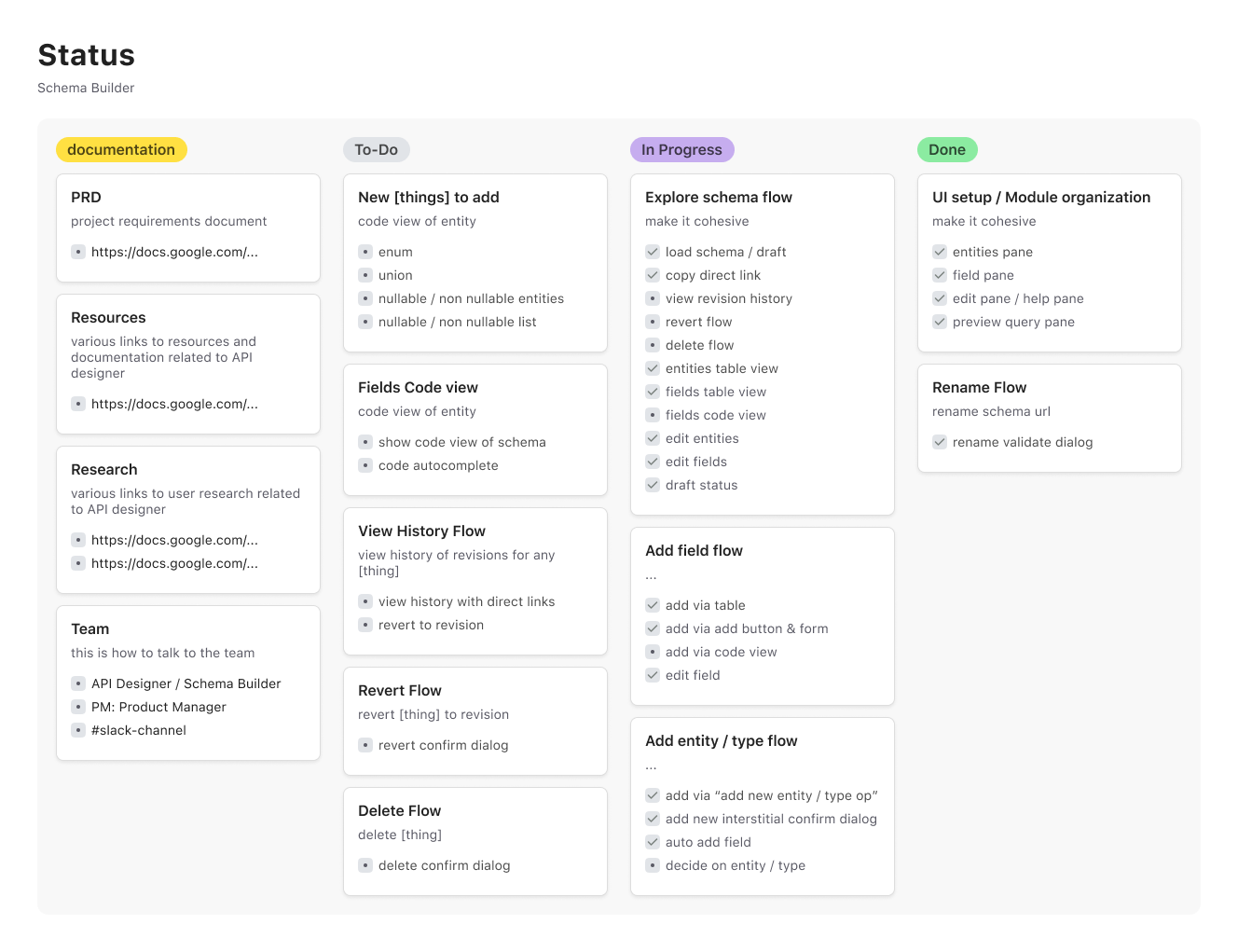
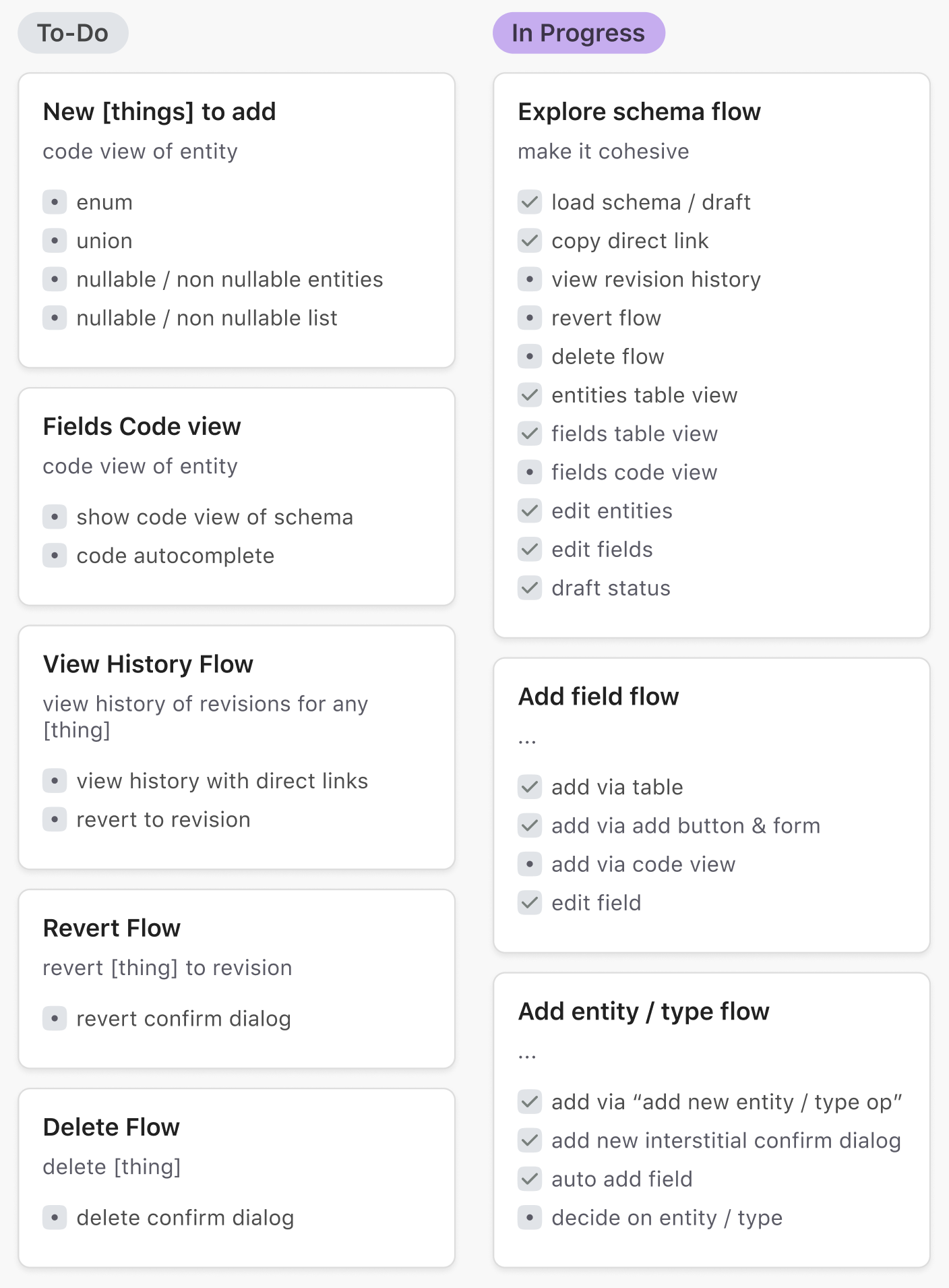
Overview of project progress: flows that were delivered, still in progress, still to-do
deliverables / wireframes
My design hypothesis and resulting task flows were generated & iterated upon in conversation with the Knowledge Graph API team and Knowledge Graph user interviews.
Multiple wireframe versions of main task flows were reviewed with the developer team for viability before high-fidelity design.
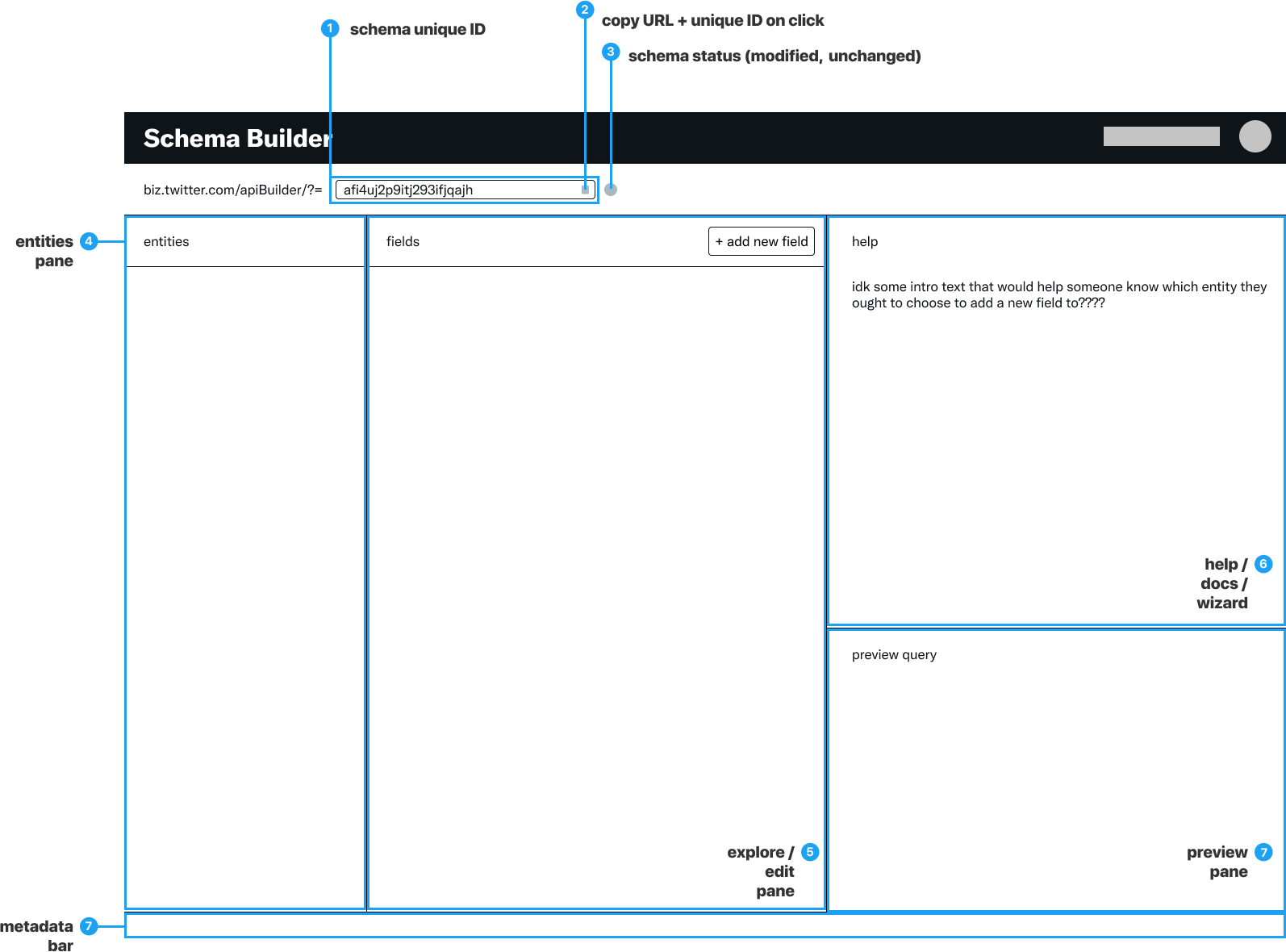
UI definition
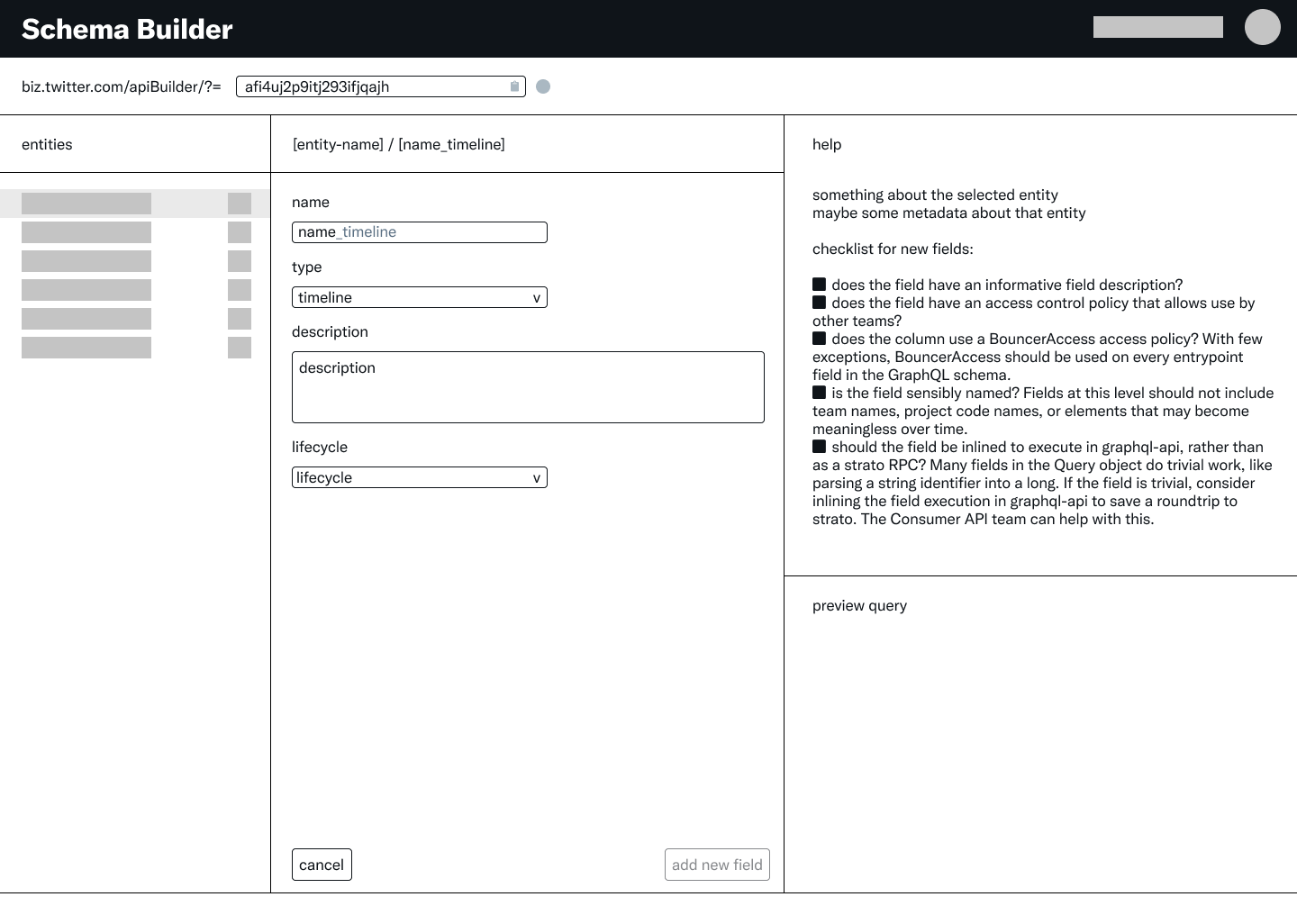
Selected wireframe closeup

Wireframe flows
deliverables / hi-fi flows
Once the wireframe base task flows were validated by both the Knowledge Graph API team as well as with expected users of the experience, work on high-fidelity mockups and interaction spec began. As a first-cut MVP, the team decided to focus on the "explore" and "add new" flows. Frequent meetings on iterations of overall task flow, information architecture, as well as micro-interactions, generated a viable MVP experience that all stakeholders approved of.
All designs utilized and extended the Twitter internal tools design system Feather. Selected screens below.
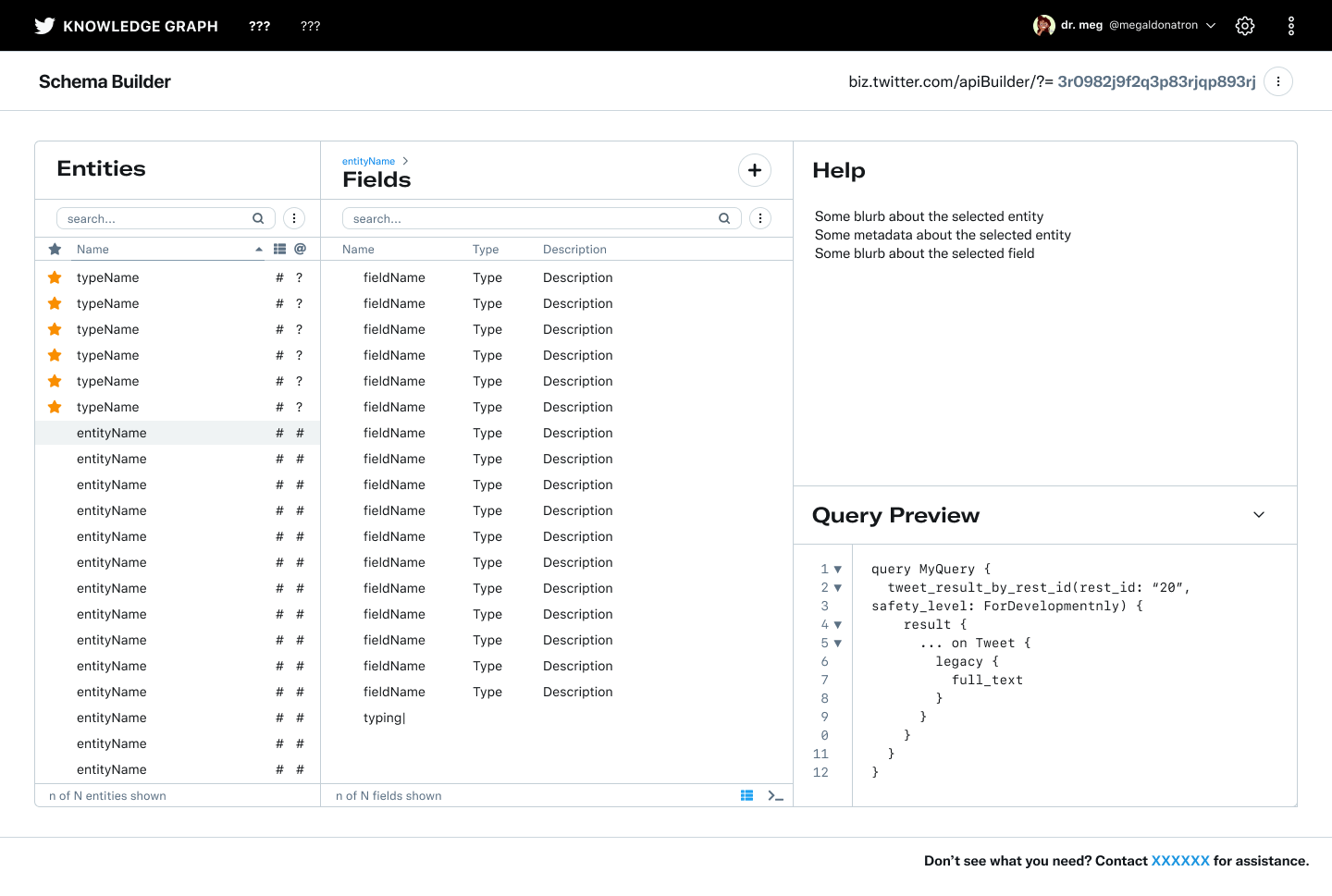
Selected empty state hi-fidelity mockup
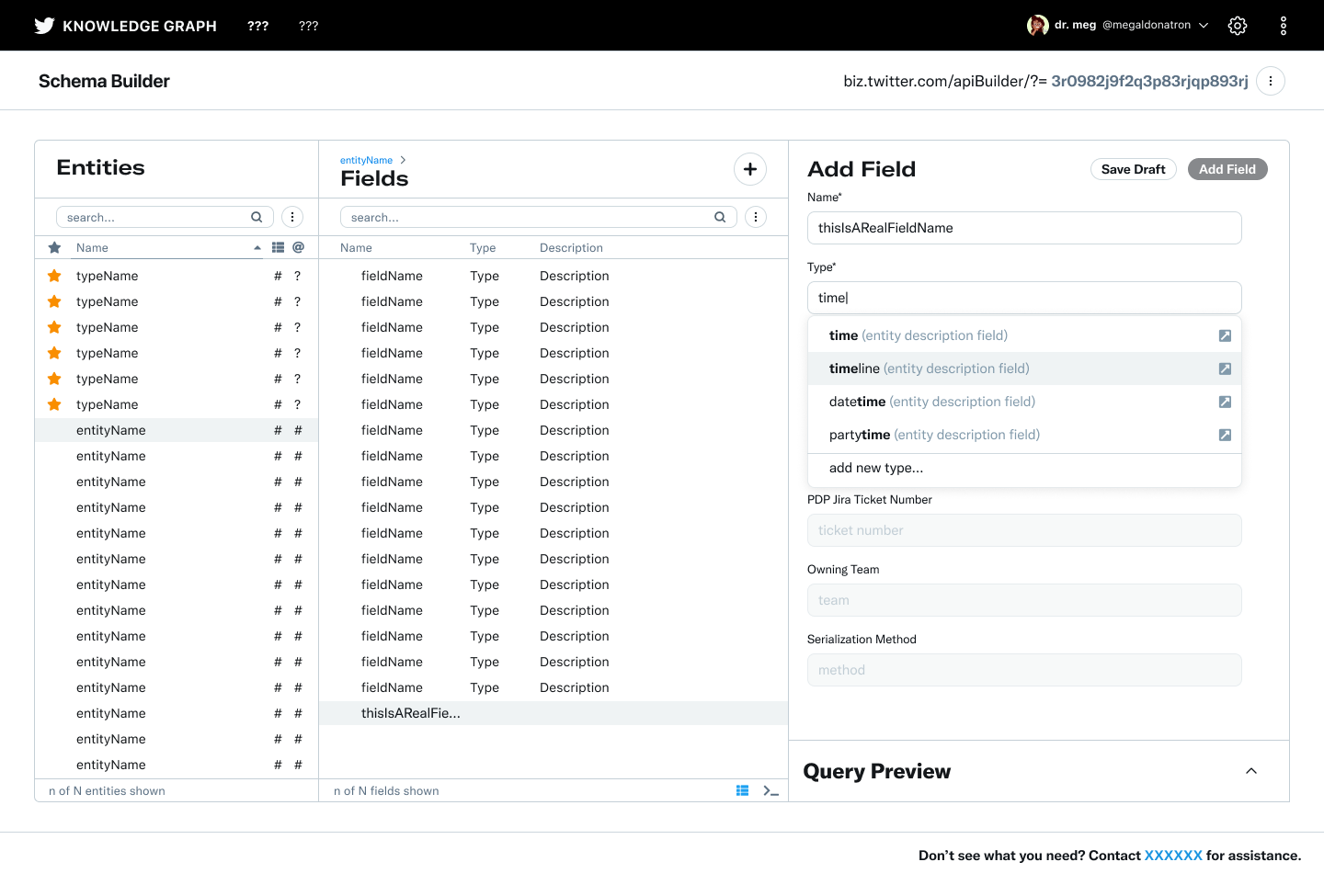
Hi-fidelity spec for add field flow with interaction
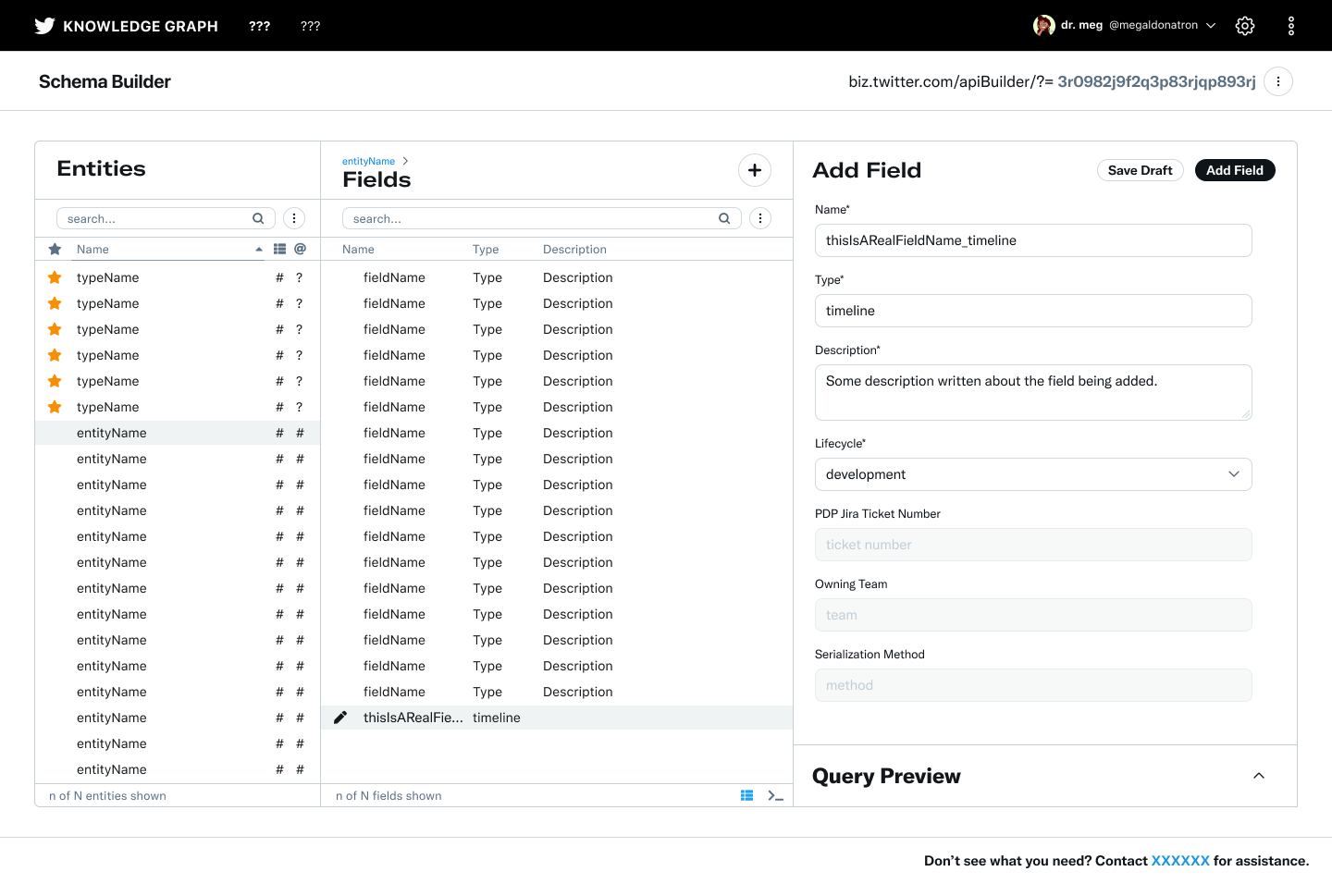
Hi-fidelity spec for add field flow filled

Overview of hi-fidelity flows
deliverables / interaction spec
Interaction spec via flow diagram embedded in the Figma project.
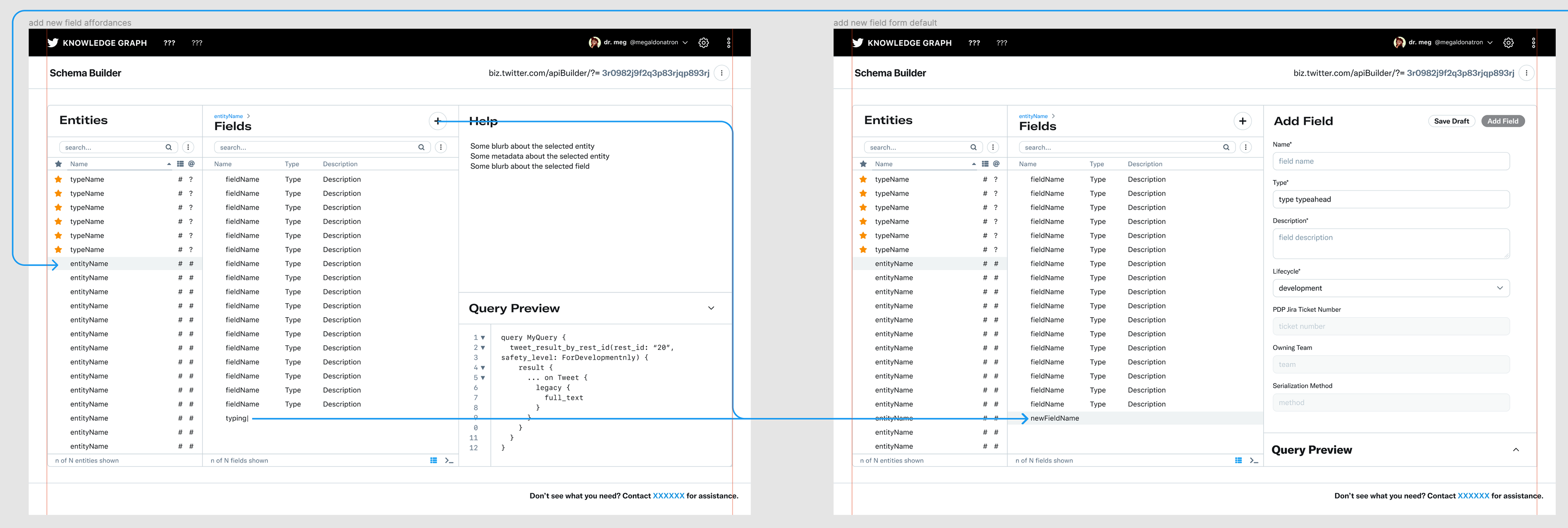
Interaction spec example for add field flow
wrap up & future directions
The MVP spec for the "explore" and "add new" flows were validated with all stakeholders and accepted by the Knowledge Graph API team for development. I left the team before development began, but am confident that the team was able to deliver an experience that worked for our expected users based on the high-fidelity mockups and interaction spec that I designed.
Future directions include the history audit and revert flows, as well as data collection and analysis for hypothesis testing. I am confident that the developed experience was a successful one as both the wireframe and high-fidelity user tests were successful.
Overview of tasks-to-be-done for schema builder project