role & responsibilities
human-in-the-loop strategist, product designer, user researcher
strategy for human-in-the-loop machine learning interaction
end to end product design (high-fidelity mockups, MVP spec, interactive prototype), ethnographic observation, user research facilitation, data analysis, integration of user feedback, stakeholder presentation
project duration: 3 months concurrent with other projects
background
Curators at Twitter use Curation Studio to curate trends that users see in the "What's Happening" box on the Twitter home page. Trends will appear automatically according to certain trendiness metrics. Curators then amend and moderate these trends to make them more useful and engaging to users by adding curated content; summarizing the trend; adding Representative Tweets (and other Twitter specific elements e.g. Events, Spaces); and adding media.
process
This Human-in-the-Loop problem was one I was extremely excited upon which to apply my Design Science process. The primary ask was initially an experience update to streamline the curator main task: curation.
In conversation with the Curation Team at Twitter I identified the Human-in-the-Loop aspect of this experience and applied a design philosophy I call Human-Centered Human-in-the-Loop. When humans are involved in training large-scale models, their task is also centered within the model training loop rather than only leveraging humans as rote training turks.
Human-Centered HiTL Talk for Twitter Curation team
problem
Currently the trend curation workflow is manual; with curators being tasked with
1. triaging related tweets
2. summarizing the trend
3. adding value
This takes a lot of time, and by the nature of manual curation, can also introduce bias for certain sources of information.
Additionally -- we have algorithms that predict trendiness and relevance of tweets, but need human intervention to validate and increase precision of these algorithms.
hypotheses
h1
By utilizing a Human-in-the-Loop system we can, 1) make the curator's task more efficient and, 2) train a recommender system on tweets related to a trend.
h2
If we are able to recommend trendy, relevant tweets to curators, we can increase the diversity of sources of relevant tweet curation elements, thus reducing the bias resulting from manual curation
experimental design
Our independent variable in this experiment was the training dataset used to train the recommender model.
Our dependent variables in this experiment were model accuracy and trend engagement.
The control group in this experiment saw trends recommended by a model trained on static data.
The treatment group in this experiment saw trends recommended by a model trained using our Human-in-the-Loop interactions.
proposed solution
We propose a Human-in-the-Loop system where the recommender system recommends candidate tweets, as well as its own confidence score for each candidate, to the curator, who then provides an explicit signal that we can use to train the recommender system in an active learning loop.
requirements
feature - the curator needs to select a candidate tweet as the Representative Tweet
upvote - the curator needs to upvote a candidate tweet, indicating that it is related to the trend and is a Good Tweet*
downvote - the curator needs to downvote a candidate tweet, indicating that this tweet is related to the trend but is a Bad Tweet*
dismiss - the curator needs to dismiss tweets that are not related to the trend
Each of these signals are utilized by the recommender system to provide better tweet candidates.
NOTE: The definitions of these implicit signals evolved as I conducted user interviews with curators. Initial requirements defined downvote and dismiss as essentially the same signal. Defining these two signals separately more accurately represented the curator's mental model of the voting task, and provided a richer signal to the model.
*👍 A Good Tweet must meet the guidelines for either a Representative Tweet or a Trendy Tweet.
*👎 A Bad Tweet either fails to meet Twitter’s Global Curation Policy and its guidelines for including individual pieces of content in curated collections, or is deemed Toxic (in accordance with Twitter’s Abusive Behavior and Hateful Conduct policies), spammy, or irrelevant by Curators.
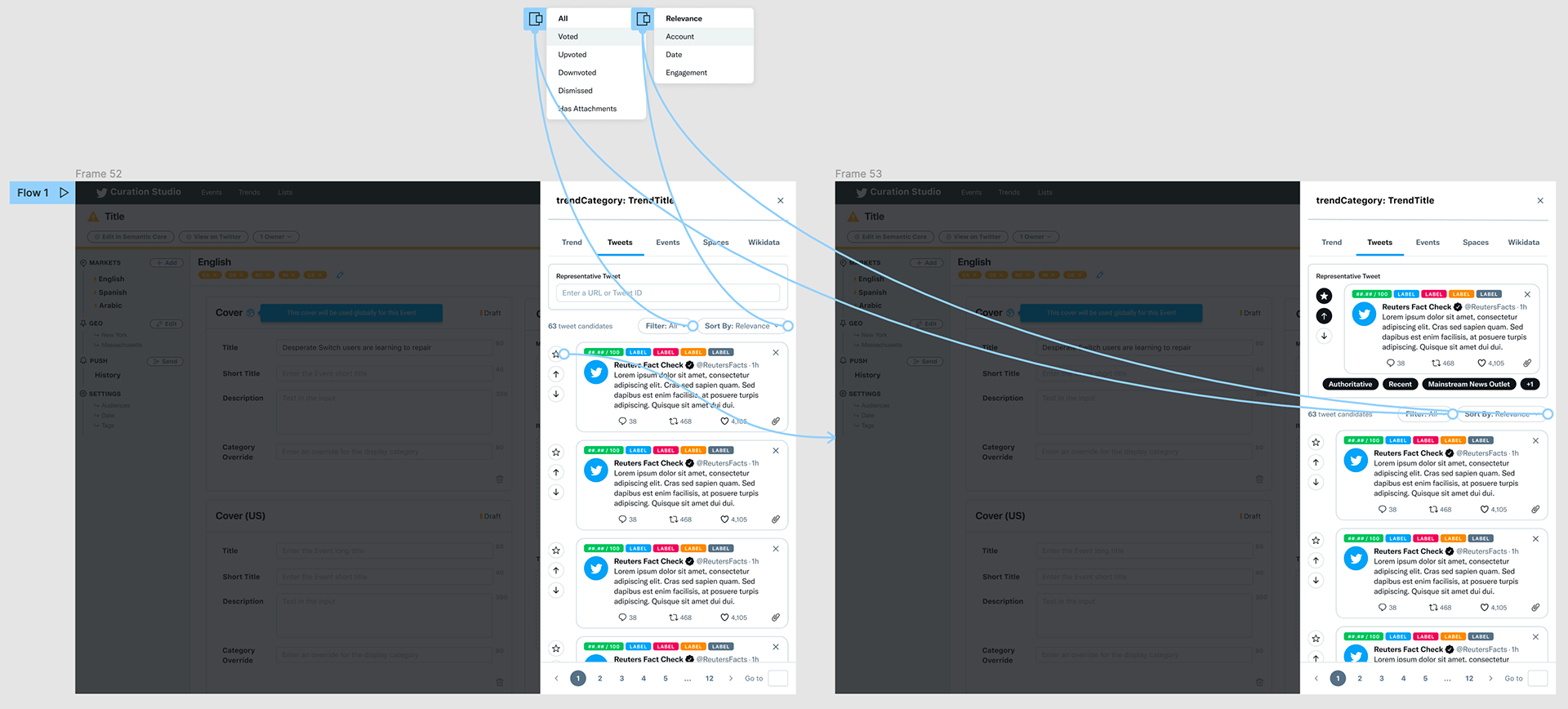
deliverables / MVP spec
I designed all high-fidelity mockups and feature variants shown below. I also annotated the mockups with 3 different versions ordered by priority; MVP, stretch and very stretch. The annotations were used both to spec engineering tickets as well as interface definition for curators.
feature highlight / delight
In order to support my stated goal of Human-Centered Human-In-The-Loop, I include playful copy and alternate states as variants in the interface. Human annotation of datasets can sometimes feel boring and repetitive, or even that the human part of the Human-in-the-Loop task is preventing the human from completing their stated goal (e.g., I want to log in but I'm prevented from doing so by a captcha).
To address automation inattention* while still providing an easy to use HiTL experience, I generated copy and variants that are playful and unique. These features were well received in user feedback sessions with curators.
* Innate human behavior where we necessarily lose focus and perform poorly on outliers or rare tasks when the vast majority of presented tasks are identical (https://pubmed.ncbi.nlm.nih.gov/29939767/).
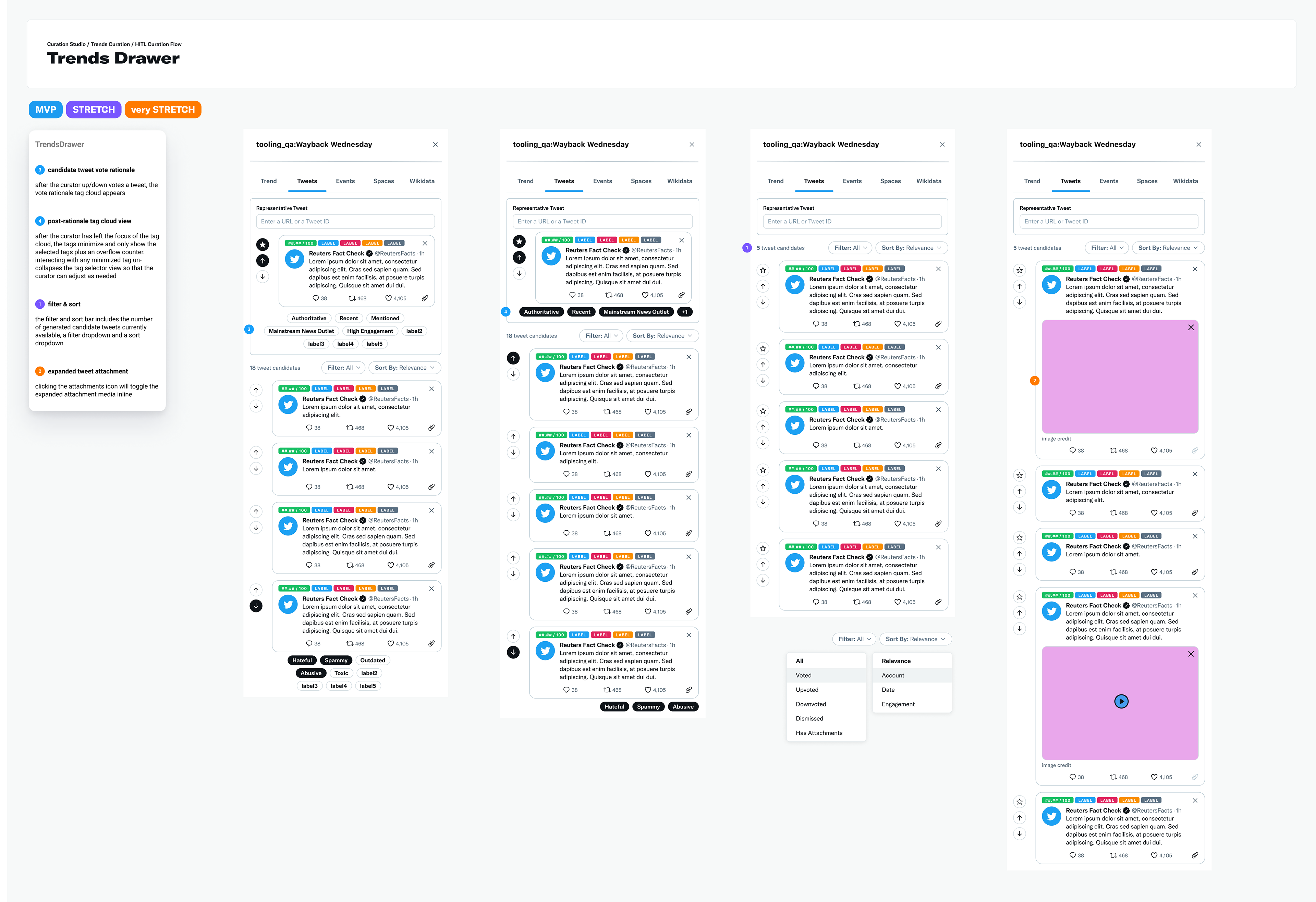
Trends drawer hi-fidelity spec ordered by MVP, stretch and very stretch
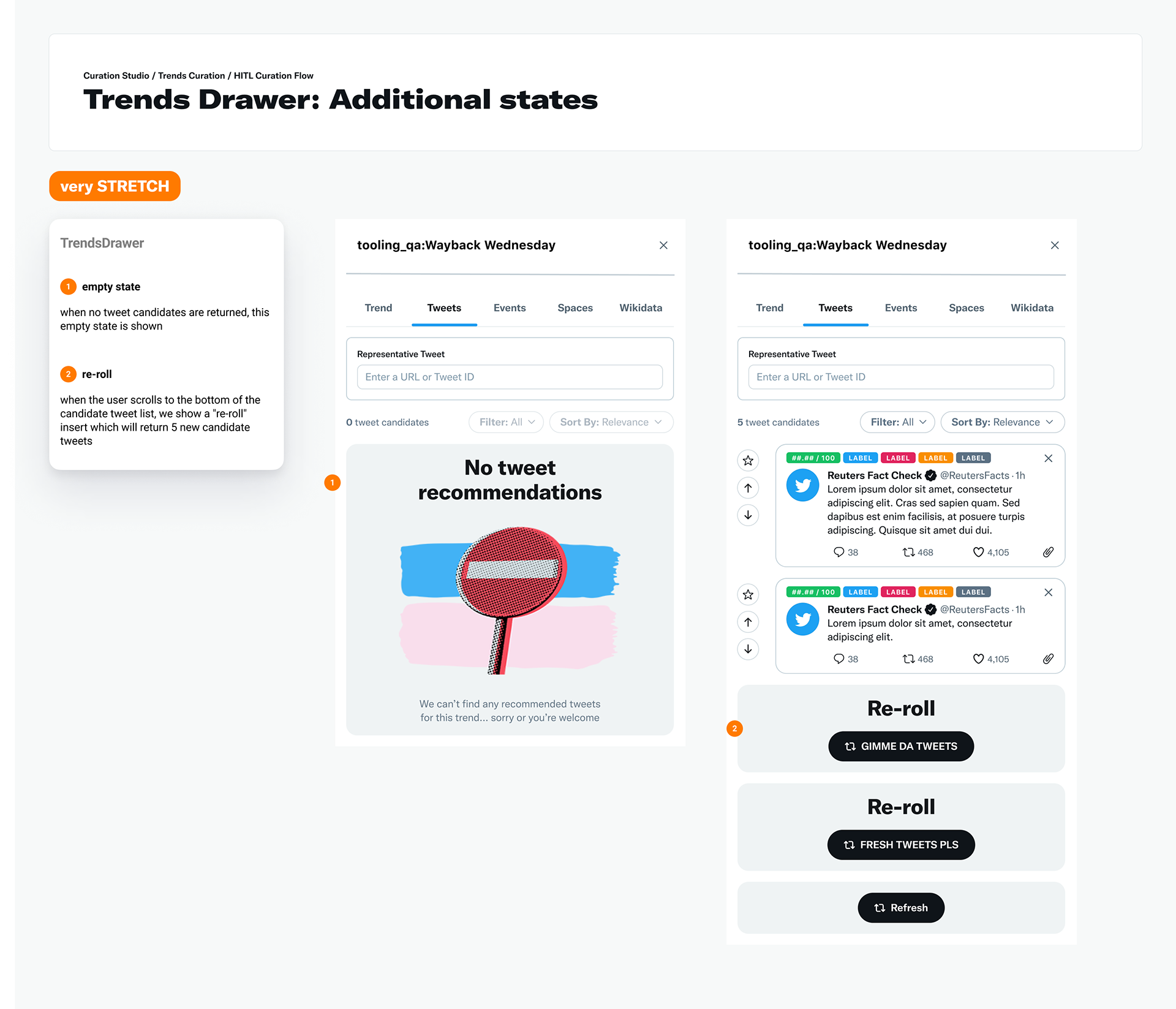
Hi-fidelity spec for additional very-stretch goals
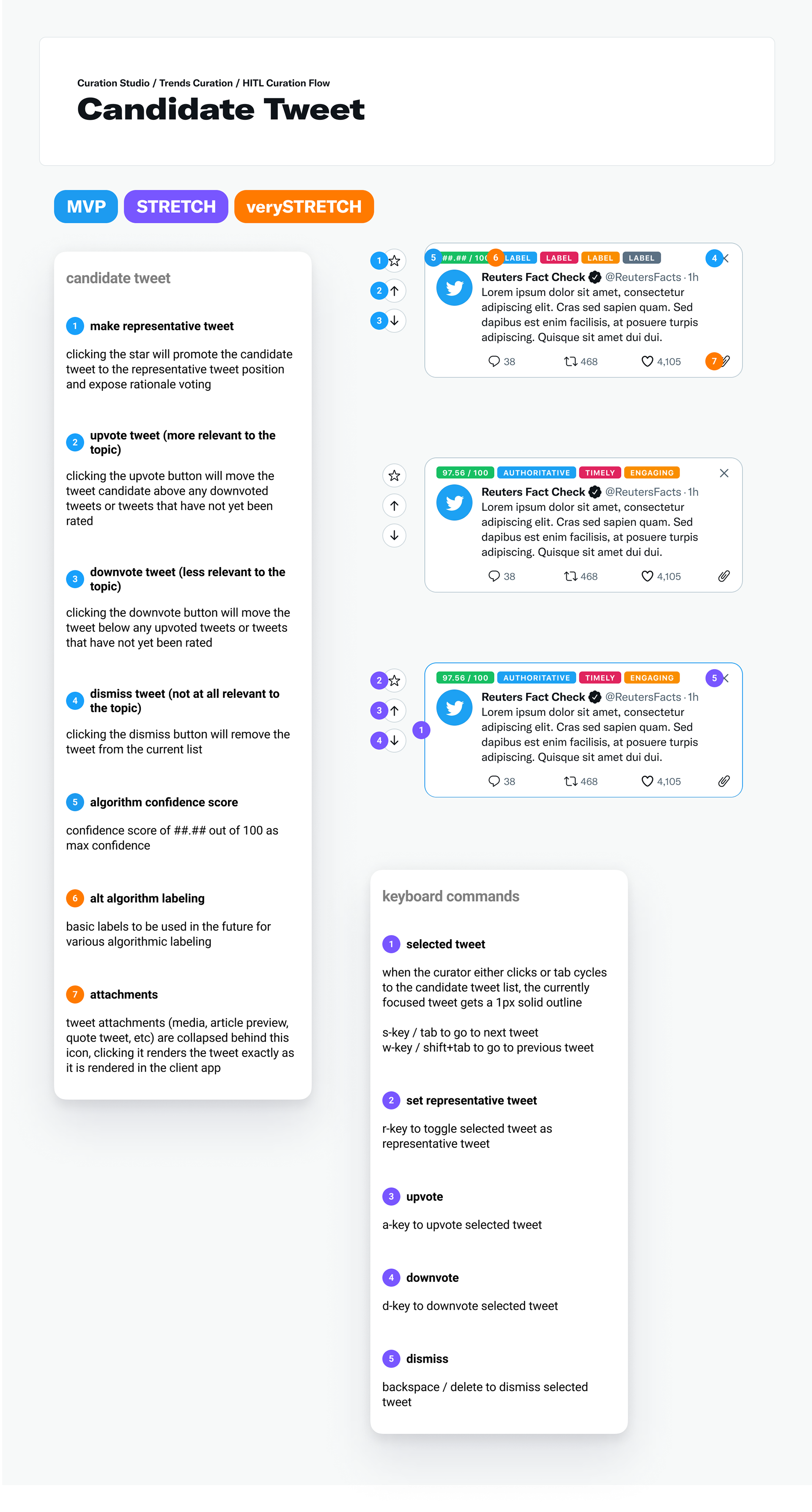
Hi-fidelity UI spec and keyboard shortcut documentation for each candidate tweet component
deliverables / prototype
I designed the interactive prototype demonstrated here, as well as the composite components and interactive variants. The prototype was used for both user studies and engineering ticket interaction spec.
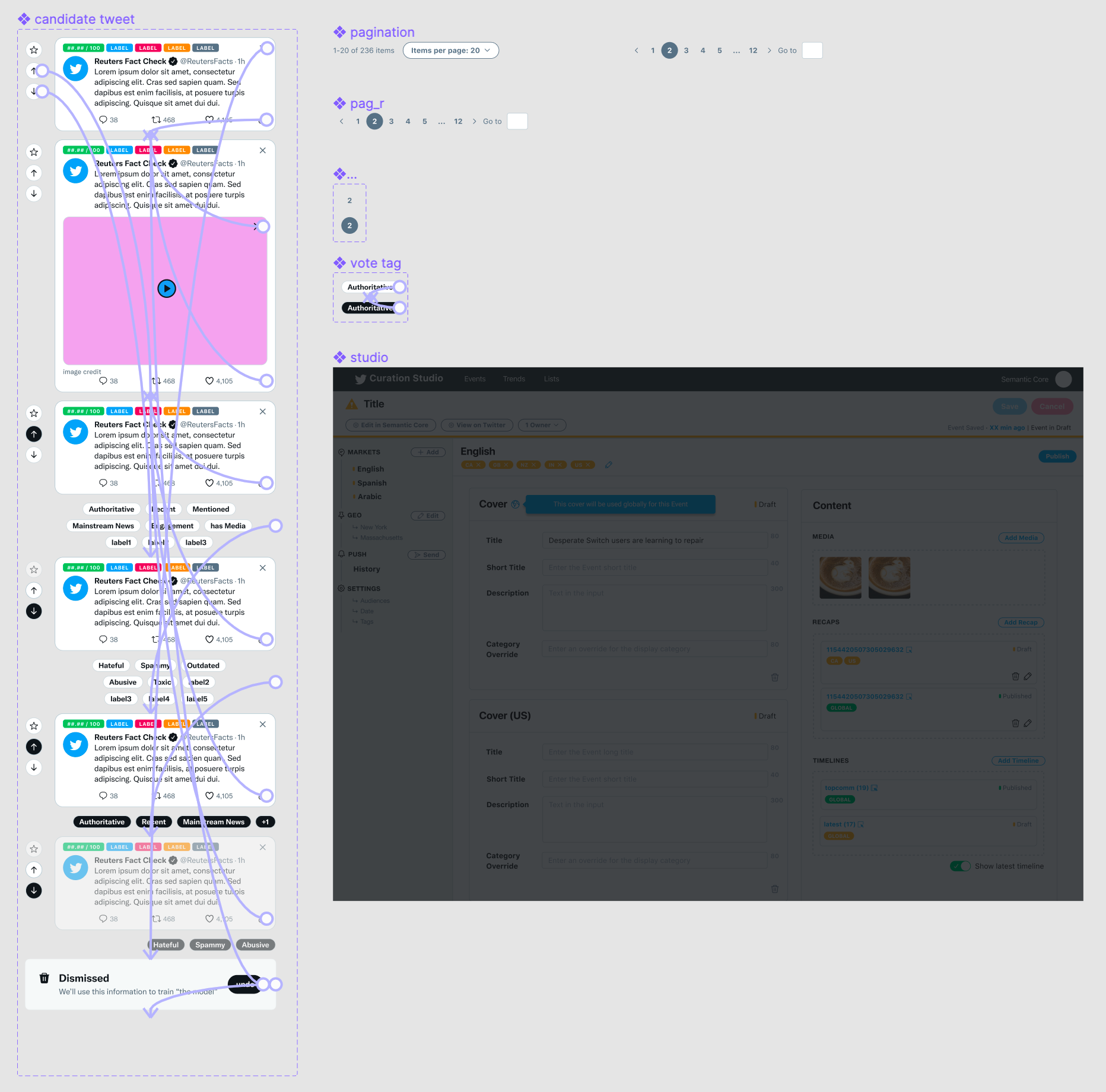
Screenshot of hi-fidelity Figma components and variants used in prototype for user and usablity tests
Screenshot of hi-fidelity Figma prototype for user and usablity tests
Prototype click-through video used for interaction spec & demonstration
data analysis
Our dependent variables in this experiment were model accuracy and trend engagement. In a statistically significant A/B test we were able to show that the treatment model had an increased accuracy of 8% (control model accuracy: 66%, treatment model accuracy: 74%), and trend engagement metrics for the treatment model recommended trends were as follows:
all trend clicks = +.8% / user
search trend clicks = +1.98%
trends feedback = +8.51%
event clicks = flat / user
search trend clicks = +1.98%
trends feedback = +8.51%
event clicks = flat / user
These results confirm our h1 hypothesis.
wrap up & future directions
Our initial hypotheses were confirmed, but further development is intended for this experience. Future directions include development and testing of the stretch and very-stretch versions.
Additionally, my prototypes include forward thinking affordances not currently supported, including expected additional algorithms (e.g. labels for classifications like 'authoritative' etc.) and explicit feedback from curators (e.g. the voting labels post up / down vote).
To further the goal of Human-Centered Human-in-the-Loop, I also envision a future version of this product that includes gamification aspects of the HITL task, with the intent of both informing curators through data summaries but also motivation through leaderboards and metric records. This metadata would also be used to test hypothesis h2: can we generate trends with more diverse & relevant representative tweets by incentivizing curators to choose diverse and relevant tweets.